Last year (2019) I spent a fair amount of time thinking about how to grow Tink’s technical platform; how to organise ourselves – alignment vs. autonomy. What processes, tooling, and policies were needed for our teams to build amazing, stable, performant things at a fast pace? Tink had essentially doubled in size yearly for four years and the growth had really pushed our engineering organization to the limits. We are now around 150 engineers. We were less than 10 engineers when I started in early 2014.
What are the foundational building blocks and processes needed for us to have twice as many teams in a year’s time?
The technical platform has grown from a Java monolith consisting of a few services that mostly were deployed at the same time, to almost 100 polyglot services (mostly microservices) being deployed continuously by lots of teams.
One thing that changes once you move towards a microservice architecture is testing. Large-scale system testing involving many applications, owned by many different teams, becomes increasingly difficult.
As I was thinking about testing strategy, I decided to give a talk at the Stockholm Go Meetup on how we do testing at Tink (slides). Ignoring the fact that the slides barely were readable (sorry!), my intention was to talk about
- the different types of tests there are; and
- the different tradeoffs we are making when choosing different testing strategies.
The talk itself came out of an observation that a lot of developers have strong opinions about testing. However, we rarely talk about what it’s actually trying to achieve, or which contexts different software can be in.
The talk started with presenting a small variant of the classical test Pyramid:
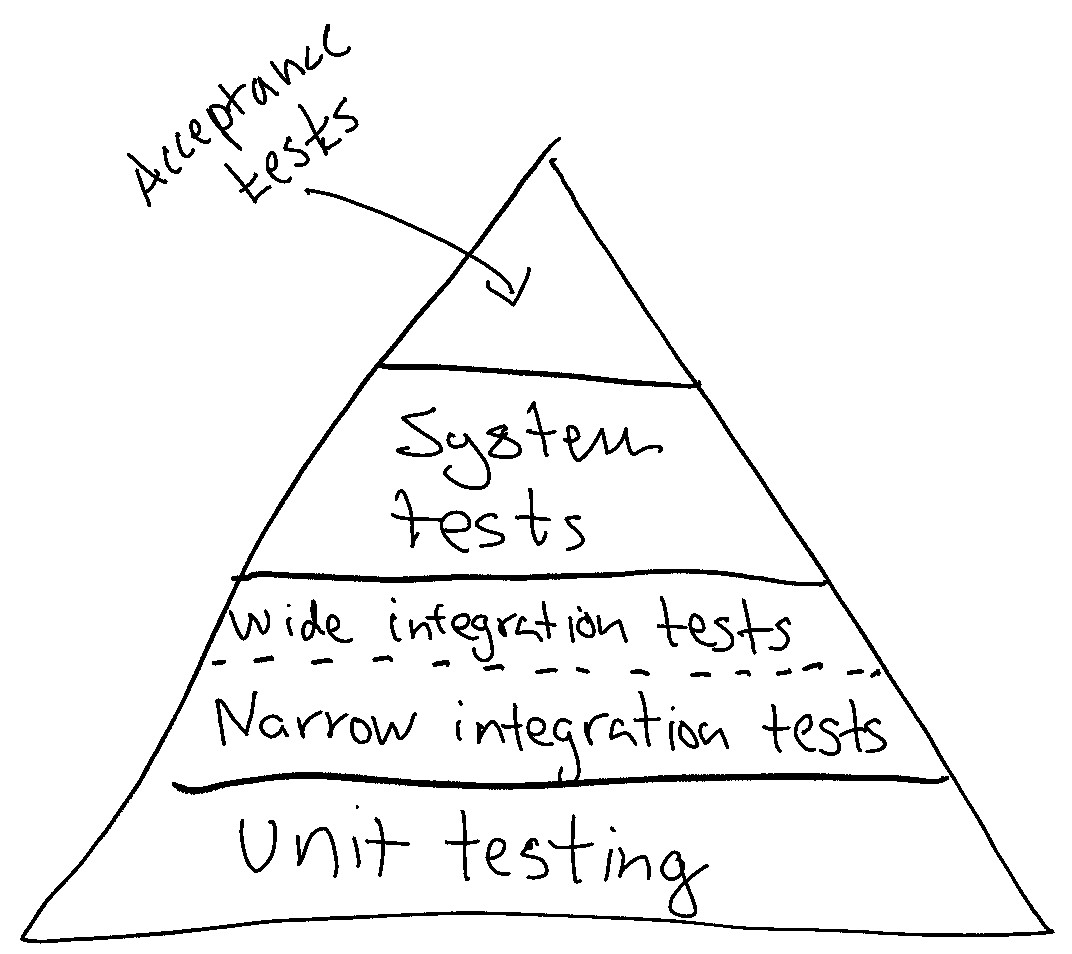
A difference between the test pyramid above and the classical test pyramid is that it distinguishes between “narrow integration tests” and “wide integration tests”. Martin Fowler has written a great article about the concept of narrow integration tests. I have more to say about that, but I’ll leave that to another blog post.
My presentation then continued making a bunch of small observations about the pyramid. Namely, the higher up in the pyramid you are, the
- the fewer tests compared to the base (thus, a Pyramid).
- the slower feedback you will get as tests are slower to execute.
- the more brittle your tests will become as they involve more components. This means they break more easily as they are coupled to a larger implementation surface is.
- the higher probability of your tests being flaky. Timeouts to a database, or starting up a web server, etc., become more common. Tests also tend to become less deterministic.
- more maintenance is needed as more components are involved.
- harder it becomes to debug as more components are involved.
- slower the tests tend to be to run as they need to initialize more components. System tests might need to read up data from a disk or external database to function.
- more complex they are to run. System tests might need configuration to run.
- closer you are to production.
- higher coverage per test as each test generally touches more components.
- harder it gets to reach higher levels of test coverage. By this, I don’t mean 100% test coverage is a goal. For a long time at Tink, we were rather system tests heavy. When we started running the same application across many production environments, running our system tests for all combinations of configurations became impossible.
Additionally, I also observed that tests in the lower part of the pyramid require “low coupling and high cohesion” (LCHC), generally considered good software design practices. That said, it is possible to have low coupling and high cohesion in an application that lacks integration and/or unit tests.
The fact that LCHC is required for unit tests and narrow integration tests also means that big balls of mud are very hard to test with such tests. For teams inheriting balls of mud it therefore makes sense to focus on a blackbox system and/or acceptance tests so they can then refactor the application to allow for smaller tests.
Furthermore, I observed how different types of tests’ costs change as software complexity increases:

The assumption here in the graph is that an “Integration test” depends on a fixed number of components. Therefore the cost of maintaining such tests does not grow as the software gets more components. This leads to the following benefit/cost ratio:
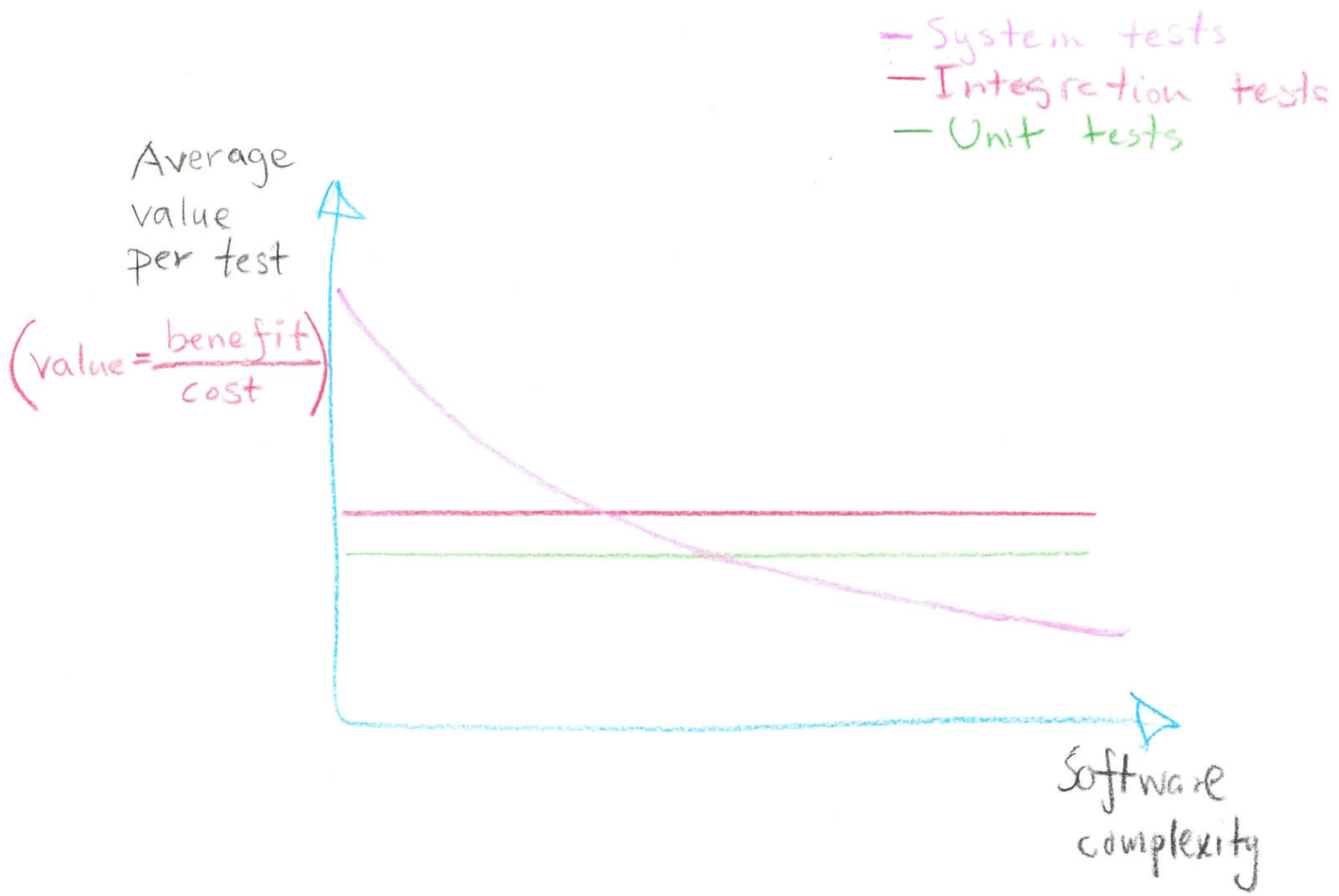
My experience over the years is that software complexity tends to grow over time. New requirements & features tend to be added, and fewer are removed. Additionally, rewrites to simplify something are rare. For good reasons! The risks in doing a rewrite are huge.
This insight is key. I believe it explains why our community is so fragmented when it comes to testing strategy – it’s because testing strategy must change with software complexity! Engineers who only have experience of low-complex software will argue for investing in a few high-level systems or wide integration tests. Engineers with experience with high complexity, tend to be wary of such tests and instead prefer unit tests and narrow integration tests.
But the reality is that none of the engineers are right. The distribution of different test types is not fixed. Instead, it changes over the life of a software. Initially, when developing a tiny microservice, I found that a single system test gives me huge benefits. As my software grows, I implement fewer and fewer system and wide integration tests – they become increasingly painful to work with.
Is there a way to avoid having to change the testing strategy over time? Perhaps. Avoid introducing complexity or make sure your core developers stay around:
With the advent of microservices, some companies have a cultural preference to keep their services small. To some extent, this can keep complexity down at the service level. However, it’s worth remembering that that instead pushes complexity to live between microservices instead. For example, investments in observability become increasingly important.
You can partially also avoid hitting the costs of software complexity by making sure you keep core competencies about an application around. Training can also, to some extent, help. That said, you are playing a rather risky game here as developers will eventually come and go. Eventually, complexity will come back biting you in the back.