In my initial post on this blog post series I wrote about the verb “to complect”. It means to braid something together. In this article, I am giving examples of things related to testing that tend to be unnecessarily complected together.
Building up a suite of maintainable tests is all about trying to avoid complecting things unless truly necessary. Notice that complecting things is necessary at times, just not always.
Tests are naturally complected with the implementation it is trying to verify. If an implementation is broken, tests will, by design, (hopefully!) break. However, all developers have a choice of how large of an implementation surface a test should cover. Have a look at this figure:
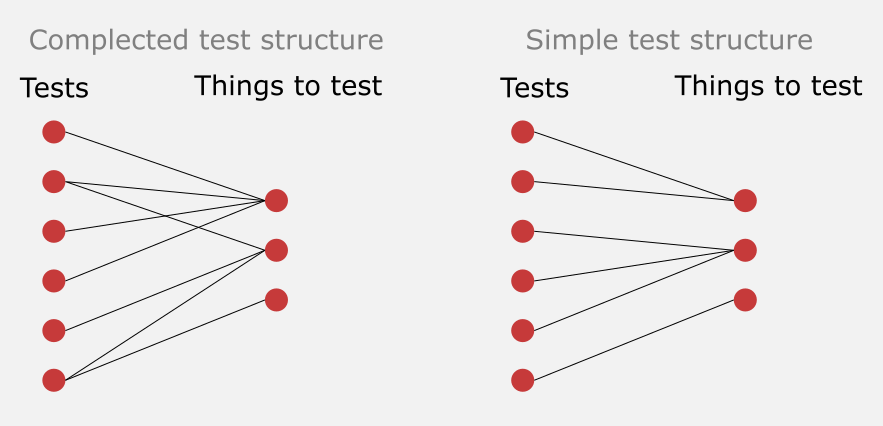
Depending on which level of coupling between tests and implementation a developer takes, you have vastly different levels of complexity. On the left side, changing an implementation will cause a lot of tests to break. Changing an implementation becomes slower and slower as you add more tests. They will all need to be updated! If you instead take the route of the right part of the figure, you will have a constant set of tests that will need to be updated over time. My previous articles “Testing strategy over time” & “On narrow integration tests” talks about this at length.
The following is a list of things I keep in my simplicity toolkit when it comes to testing:
Test outcome over implementation Link to heading
In my introduction above I spoke about the cost of updating tests every time I modify an implementation. It has a high cost.
To reduce the likelihood of that happening, tests should verify what (outcome) is being done in an implementation, not how it’s being done. In other words, your tests should not depend on the inner nitty-gritty details of an implementation. A different way of looking at it is that a rewrite of how a class or a function does something shouldn’t require changing any of the tests as long as the outcome is the same. This will make refactoring a lot easier.
Other test doubles over mocks Link to heading
According to Martin Fowler, a “test double” is
[…] a generic term for any case where you replace a production object for testing purposes.
Mocks, spies, fakes, stubs, and dummies are all examples of test doubles. Fowler further defines a Mock as
[…] pre-programmed with expectations which form a specification of the calls they are expected to receive.
As already stated in the previous section, tests should be coupled to outcome, not implementation. Mocks tend to be horrible when it comes to this. You send in an object into your implementation and it’s preprogrammed exactly how it should behave depending on the implementation. I think Ian Cooper explains it quite well here.
Another problem with mocks is that they tend to be quite complex to use. I programmed professionally in Java for many many years and still had to look up things in the reference documentation for Mockito. Other types of test doubles tend to be much simpler to use and understand.
Strictly speaking, I only see two use cases for mocks:
- If I am coding in a strictly typed programming language, and I am using a third-party library that does not adhere to the dependency inversion principle. Ie., it doesn’t have interfaces that I can implement to change its internal behavior of it.
- Certain hackery when it comes to third-party libraries that use
statics and singletons.
I avoid mocks as much as I can. I guess that makes me a classicist tester.
Given/When/Then over unclarity what is being tested Link to heading
A common structure for automated tests is to split them up in three stages, “Given, When, Then” or “Arrange, Act, Assert” (two variants of the same thing). Here is an example:
def my_test():
# Given two numbers:
a = random_number()
b = random_number()
# When I call the sum function:
c = sum([a, b])
# Then the result should be the sum of the numbers
assert c == a + b
Compare the above test to this:
def my_test():
a = random_number()
b = random_number()
c = sum([a, b])
assert c == a + b
The latter example makes it unclear what it is trying to test; Are we checking
if the results return from random_number() can be summed? Or are we checking
that the behavior of sum(...) behaves as we expect?
“I don’t dare to remove this test, because it might be testing something there isn’t a test for elsewhere.”
If we don’t clarify what we are testing (When or Act), developers don’t dare to remove tests over time. Suddenly we have a large evergrowing test suite - complecting our tests with implementation more and more. You end up having to update tons of tests every time you make a change to an implementation.
The above problem can be a huge headache in larger code bases.
Naming test by outcome over how Link to heading
Related to the above, it’s important to name your tests for the behavior
they are testing, not how it is being done. This includes mentioning the
expected outcome. For my example tests above,
testThatTwoRandomNumbersSumUpCorrectly is a much better name that
testThatSumLoopingWorks. That the sum(...) function uses a loop internally
is irrelevant. And “works” says nothing of the expected outcome.
This article looks to be a good one when it comes to the naming of tests if you would like to know more.
Unit tests over integration tests Link to heading
An integration test is a test that, by definition, tests multiple units together. Compare that to a unit test which by definition only tests a single unit. This means, by definition, that an integration test complects with more parts of your implementation.
My article “Testing Strategy Over Time” talked about this at length.
This practice aligns very well with the classical Testing Pyramid.
Narrow integration tests over (general) integration tests Link to heading
…and if I write an integration test, I make it narrow. Narrow in this case means that to test an integrated set of units, I test how they integrate and work with each other pairwise. If they all work well with each other pairwise (narrow integration test), there is no need to test them altogether (wide integration test).
For example, I test that two layers in my application interact the way they should, instead of testing all layers together. This means, that I don’t need an actual database to test the HTTP controller layer. Instead, I make sure that the HTTP layer delegates calls properly to the business/service layer, etc.
My article “On narrow integration tests” talked about this at length.
Testing in production over end-to-end tests Link to heading
Tests are in a way a liability. There is a cost to maintaining them. The wider the integration tests, the higher the cost over time. The widest possible integration tests, and thus the most expensive to maintain, is an end-to-end test. It is a test that starts up your entire application, needing all your supporting infrastructure in place (databases, queues, caches…), to be able to run.
The most realistic test is the one when a user tests any functionality. Nothing can beat it. Users will double click on the buttons you’ve only clicked once, and they will enter 1000 characters in the text field you entered 10 characters.
While, having an automated test that makes sure you application can start can be useful, getting it out in production to test with actual users has the benefit of getting feedback quicker and not slowing down your development with complex, slow, and brittle tests.
Don’t get me wrong, though! To be able to test in production you need a good foundation:
- Quick deploys.
- A solid CI/CD system that can do a gradual rollout.
- A feature flag system to toggle new features for a subset of users.
- Solid observability in place to understand the success rate for user behaviours.